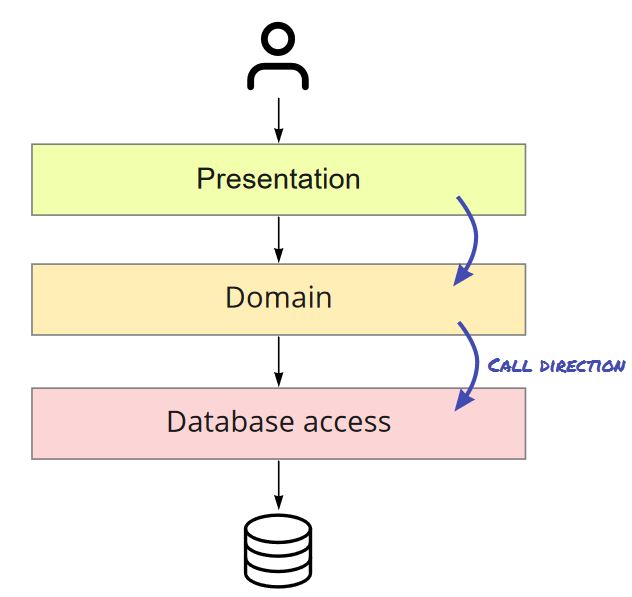
Usually we use standard data exchange formats like JSON or XML with REST web services. However, many REST services have at least some operations that can be hard to fulfill with just JSON or XML. Examples are uploads of product images, data imports using uploaded CSV files or generation of downloadable PDF reports.
In this post we focus on those operations, which are often categorized as file down- and uploads. This is a bit flaky as sending a simple JSON document can also be seen as a (JSON) file upload operation.
Think about the operation you want to express
A common mistake is to focus on the specific file format that is required for the operation. Instead, we should think about the operation we want to express. The file format just decides the Media Type used for the operation.
For example, assume we want to design an API that let users upload an avatar image to their user account.
Here, it is usually a good idea to separate the avatar image from the user account resource for various reasons:
- The avatar image is unlikely to change so it might be a good candidate for caching. On the other, hand the user account resource might contain things like the last login date which changes frequently.
- Not all clients accessing the user account might be interested in the avatar image. So, bandwidth can be saved.
- For clients it is often preferable to load images separately (think of web applications using <img> tags)
The user account resource might be accessible via:
/users/<user-id>
We can come up with a simple sub-resource representing the avatar image:
/users/<user-id>/avatar
Uploading an avatar is a simple replace operation which can be expressed via PUT:
PUT /users/<user-id>/avatar
Content-Type: image/jpeg
<image data>
In case a user wants to delete his avatar image, we can use a simple DELETE operation:
DELETE /users/<user-id>/avatar
And of course clients need a way to show to avatar image. So, we can provide a download operation with GET:
GET /users/<user-id>/avatar
which returns
HTTP/1.1 200 Ok
Content-Type: image/jpeg
<image data>
In this simple example we use a new sub-resource with common update, delete, get operations. The only difference is we use an image media type instead of JSON or XML.
Let's look at a different example.
Assume we provide an API to manage product data. We want to extend this API with an option to import products from an uploaded CSV file. Instead of thinking about file uploads we should think about a way to express a product import operation.
Probably the simplest approach is to send a POST request to a separate resource:
POST /product-import
Content-Type: text/csv
<csv data>
Alternatively, we can also see this as a bulk operation for products. As we learned in another post about bulk operations with REST, the PATCH method is a possible way to express a bulk operation on a collection. In this case, the CSV document describes the desired changes to product collection.
For example:
PATCH /products
Content-Type: text/csv
action,id,name,price
create,,Cool Gadget,3.99
create,,Nice cap,9.50
delete,42,,
This example creates two new products and deletes the product with id 42.
Processing file uploads can take a considerable amount of time. So think about designing it as an asynchronous REST operation.
Mixing files and metadata
In some situations we might need to attach additional metadata to a file. For example, assume we have an API where users can upload holiday photos. Besides the actual image data a photo might also contain a description, a location where it was taken and more.
Here, I would (again) recommend using two separate operations for similar reasons as stated in the previous section with the avatar image. Even if the situation is a bit different here (the data is directly linked to the image) it is usually the simpler approach.
In this case, we can first create a photo resource by sending the actual image:
POST /photos
Content-Type: image/jpeg
<image data>
As response we get:
HTTP/1.1 201 Created
Location: /photos/123
After that, we can attach additional metadata to the photo:
PUT /photos/123/metadata
Content-Type: application/json
{
"description": "Nice shot of a beach in hawaii",
"location": "hawaii",
"filename": "hawaii-beach.jpg"
}
Of course we can also design it the other way around and send the metadata before the image.
Embedding Base64 encoded files in JSON or XML
In case splitting file content and metadata in seprate requests it not possible, we can embed files into JSON / XML documents using Base64 encoding. With Base64 encoding we can convert binary formats to a text representation which can be integrated in other text based formats, like JSON or XML.
An example request might look like this:
POST /photos
Content-Type: application/json
{
"width": "1280",
"height": "920",
"filename": "funny-cat.jpg",
"image": "TmljZSBleGFt...cGxlIHRleHQ="
}
Mixing media-types with multipart requests
Another possible approach to transfer image data and metadata in a single request / response are multipart media types.
Multipart media types require a boundary parameter that is used as delimiter between different body parts. The following request consists of two body parts. The first one contains the image while the second part contains the metadata.
For example
POST /photos
Content-Type: multipart/mixed; boundary=foobar
--foobar
Content-Type: image/jpeg
<image data>
--foobar
Content-Type: application/json
{
"width": "1280",
"height": "920",
"filename": "funny-cat.jpg"
}
--foobar--
Unfortunately multipart requests / responses are often hard to work with. For example, not every REST client might be able to construct these requests and it can be hard to verify responses in unit tests.
Interested in more REST related articles? Have a look at my REST API design page.