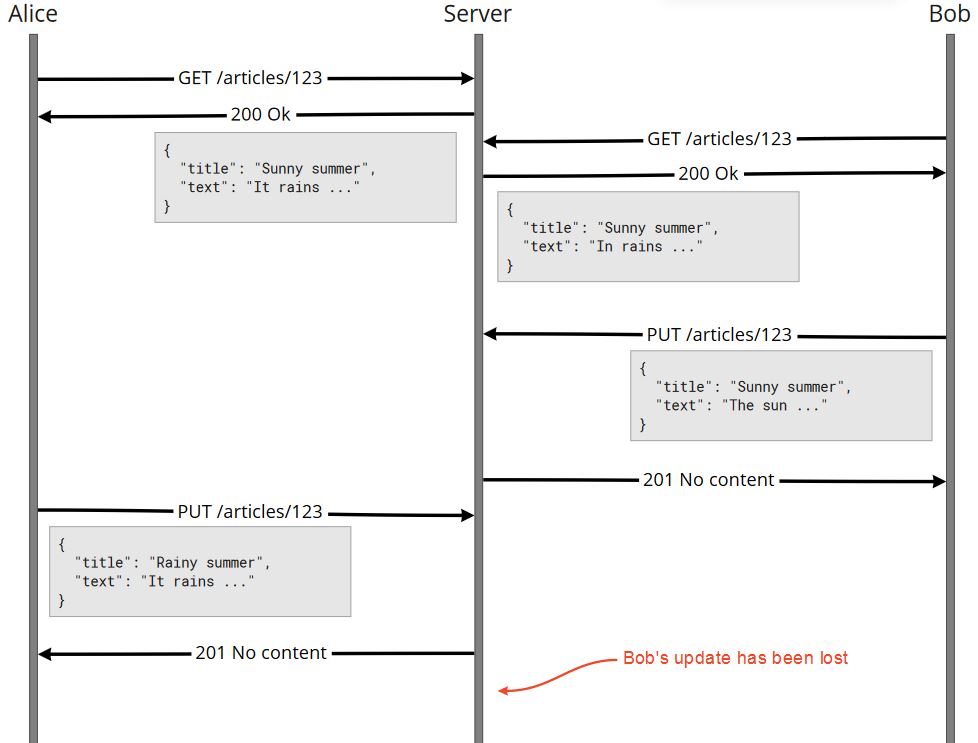
Bulk (or batch) operations are used to perform an action on more than one resource in single request. This can help reduce networking overhead. For network performance it is usually better to make fewer requests instead of more requests with less data.
However, before adding support for bulk operations you should think twice if this feature is really needed. Often network performance is not what limits request throughput. You should also consider techniques like HTTP pipelining as alternative to improve performance.
When implementing bulk operations we should differentiate between two different cases:
- Bulk operations that group together many arbitrary operations in one request. For example: Delete product with id 42, create a user named John and retrieve all product-reviews created yesterday.
- Bulk operations that perform one operation on different resources of the same type. For example: Delete the products with id 23, 45, 67 and 89.
In the next section we will explore different solutions that can help us with both situations. Be aware that the shown solutions might not look very REST-like. Bulk operations in general are not very compatible with REST constraints as we operate on different resources with a single request. So there simply is no real REST solution.
In the following examples we will always return a synchronous response. However, as bulk operations usually take longer to process it is likely you are also interested in an asynchronous processing style. In this case, my post about asynchronous operations with REST might also be interesting to you.
Expressing multiple operations within the request body
Probably a way that comes to mind quickly is to use a standard data format like JSON to define a list of desired operations.
Let's start with a simple example request:
POST /batch
[
{
"path": "/products",
"method": "post",
"body": {
"name": "Cool Gadget",
"price": "$ 12.45 USD"
}
}, {
"path": "/users/43",
"method": "put",
"body": {
"name": "Paul"
}
},
...
]
We use a generic /batch endpoint that accepts a simple JSON format to describe desired operations using URIs and HTTP methods. Here, we want to execute a POST request to /products and a PUT request to /users/43.
A response body for the shown request might look like this:
[
{
"path": "/products",
"method": "post",
"body": {
"id": 123,
"name": "Cool Gadget",
"price": "$ 12.45 USD"
},
"status": 201
}, {
"path": "/users/43",
"method": "put",
"body": {
"id": 43,
"name": "Paul"
},
"status": 200
},
...
]
For each requested operation we get a result object containing the URI and HTTP method again. Additionally we get the status code and response body for each operation.
This does not look too bad. In fact, APIs like this can be found in practice. Facebook for example uses a similiar approach to batch multiple Graph API requests.
However, there are some things to consider with this approach:
How are the desired operations executed on the server side? Maybe it is implemented as simple method call. It is also possible to create a real HTTP requests from the JSON data and then process those requests. In this case, it is important to think about request headers which might contain important information required by the processing endpoint (e.g. authentication tokens, etc.).
Headers in general are missing in this example. However, headers might be important. For example, it is perfectly viable for a server to respond to a POST request with HTTP 201 and an empty body (see my post about resource creation). The URI of the newly created resource is usually transported using a Location header. Without access to this header the client might not know how to look up the newly created resource. So think about adding support for headers in your request format.
In the example we assume that all requests and responses use JSON data as body which might not always be the case (think of file uploads for example). As alternative we can define the request body as string which gives us more flexibility. In this case, we need to escape JSON double quotes which can be awkward to read:
An example request that includes headers and uses a string body might look like this:
[
{
"path": "/users/43",
"method": "put",
"headers": [{
"name": "Content-Type",
"value": "application/json"
}],
"body": "{ \"name\": \"Paul\" }"
},
...
]
Multipart Content-Type for the rescue?
In the previous section we essentially translated HTTP requests and responses to JSON so we can group them together in a single request. However, we can do the same in a more standardized way with multipart content-types.
A multipart Content-Type header indicates that the HTTP message body consists of multiple distinct body parts and each part can have its own Content-Type. We can use this to merge multiple HTTP requests into a single multipart request body.
A quick note before we look at an example: My example snippets for HTTP requests and responses are usually simplified (unnecessary headers, HTTP versions, etc. might be skipped). However, in the next snippet we pack HTTP requests into the body of a multipart request requiring correct HTTP syntax. Therefore, the next snippets use the exact HTTP message syntax.
Now let's look at an example multipart request containing two HTTP requests:
1 POST http://api.my-cool-service.com/batch HTTP/1.1
2 Content-Type: multipart/mixed; boundary=request_delimiter
3 Content-Length: <total body length in bytes>
4
5 --request_delimiter
6 Content-Type: application/http
7 Content-ID: fa32d92f-87d9-4097-9aa3-e4aa7527c8a7
8
9 POST http://api.my-cool-service.com/products HTTP/1.1
10 Content-Type: application/json
11
12 {
13 "name": "Cool Gadget",
14 "price": "$ 12.45 USD"
15 }
16 --request_delimiter
17 Content-Type: application/http
18 Content-ID: a0e98ffb-0b62-42a1-a321-54c6e9ef4c99
19
20 PUT http://api.my-cool-service.com/users/43 HTTP/1.1
21 Content-Type: application/json
22
23 {
24 "section": "Section 2"
25 }
26 --request_delimiter--
Multipart content types require a boundary parameter. This parameter specifies the so-called encapsulation boundary which acts like a delimiter between different body parts.
Quoting the RFC:
The encapsulation boundary is defined as a line consisting entirely of two hyphen characters ("-", decimal code 45) followed by the boundary parameter value from the Content-Type header field.
In line 2 we set the Content-Type to multipart/mixed with a boundary parameter of request_delimiter. The blank line after the Content-Length header separates HTTP headers from the body. The following lines define the multipart request body.
We start with the encapsulation boundary indicating the beginning of the first body part. Next follow the body part headers. Here, we set the Content-Type header of the body part to application/http which indicates that this body part contains a HTTP message. We also set a Content-Id header which we can be used to identify a specific body part. We use a client generated UUID for this.
The next blank line (line 8) indicates that now the actual body part begins (in our case that's the embedded HTTP request). The first body part ends with the encapsulation boundary at line 16.
After the encapsulation boundary, follows the next body part which uses the same format as the first one.
Note that the encapsulation boundary following the last body part contains two additional hyphens at the end which indicates that no further body parts will follow.
A response to this request might follow the same principle and look like this:
1 HTTP/1.1 200
2 Content-Type: multipart/mixed; boundary=response_delimiter
3 Content-Length: <total body length in bytes>
4
5 --response_delimiter
6 Content-Type: application/http
7 Content-ID: fa32d92f-87d9-4097-9aa3-e4aa7527c8a7
8
9 HTTP/1.1 201 Created
10 Content-Type: application/json
11 Location: http://api.my-cool-service.com/products/123
12
13 {
14 "id": 123,
15 "name": "Cool Gadget",
16 "price": "$ 12.45 USD"
17 }
18 --response_delimiter
19 Content-Type: application/http
20 Content-ID: a0e98ffb-0b62-42a1-a321-54c6e9ef4c99
21
22 HTTP/1.1 200 OK
23 Content-Type: application/json
24
25 {
26 "id": 43,
27 "name": "Paul"
28 }
29 --response_delimiter--
This multipart response body contains two body parts both containing HTTP responses. Note that the first body part also contains a Location header which should be included when sending a HTTP 201 (Created) response status.
Multipart messages seem like a nice way to merge multiple HTTP messages into a single message as it uses a standardized and generally understood technique.
However, there is one big caveat here. Clients and the server need to be able to construct and process the actual HTTP messages in raw text format. Usually this functionality is hidden behind HTTP client libraries and server side frameworks and might not be easily accessible.
Bulk operations on REST resources
In the previous examples we used a generic /batch endpoint that can be used to modify many different types of resources in a single request. Now we will apply bulk operations on a specific set of resources to move a bit into a more rest-like style.
Sometimes only a single operation needs to support bulk data. In such a case, we can simply create a new resource that accepts a collection of bulk entries.
For example, assume we want to import a couple of products with a single request:
POST /product-import
[
{
"name": "Cool Gadget",
"price": "$ 12.45 USD"
},
{
"name": "Very cool Gadget",
"price": "$ 19.99 USD"
},
...
]
A simple response body might look like this:
[
{
"status": "imported",
"id": 234235
},
{
"status": "failed"
"error": "Product name too long, max 15 characters allowed"
},
...
]
Again we return a collection containing details about every entry. As we provide a response to a specific operation (importing products) there is not need to use a generic response format. Instead, we can use a specific format that communicates the import status and potential import errors.
Partially updating collections
In a previous post we learned that PATCH can be used for partial modification of resources. PATCH can also use a separate format to describe the desired changes.
Both sound useful for implementing bulk operations. By using PATCH on a resource collection (e.g. /products) we can partially modify the collection. We can use this to add new elements to the collection or update existing elements.
For example we can use the following snippet to modify the /products collection:
PATCH /products
[
{
"action": "replace",
"path": "/123",
"value": {
"name": "Yellow cap",
"description": "It's a cap and it's yellow"
}
},
{
"action": "delete",
"path": "/124",
},
{
"action": "create",
"value": {
"name": "Cool new product",
"description": "It is very cool!"
}
}
]
Here we perform three operations on the /products collection in a single request. We update resource /products/123 with new information, delete resource /products/124 and create a completely new product.
A response might look somehow like this:
[
{
"action": "replace",
"path": "/123",
"status": "success"
},
{
"action": "delete",
"path": "/124",
"status": "success"
}, {
"action": "create",
"status": "success"
}
]
Here we need to use a generic response entry format again as it needs to be compatible to all possible request actions.
However, it would be too easy without a huge caveat: PATCH requires changes to be applied atomically.
The RFC says:
The server MUST apply the entire set of changes atomically and never provide [..] a partially modified representation. If the entire patch document cannot be successfully applied, then the server MUST NOT apply any of the changes.
I usually would not recommend to implement bulk operation in an atomic way as this can increase complexity a lot.
A simple workaround to be compatible with the HTTP specifications is to create a separate sub-resource and use POST instead of PATCH.
For example:
POST /products/batch
(same request body as the previous PATCH request)
If you really want to go the atomic way, you might need to think about the response format again. In this case, it is not possible that some requested changes are applied while others are not. Instead you need to communicate what requested changes failed and which could have been applied if everything else would have worked.
In this case, a response might look like this:
[
{
"action": "replace",
"path": "/123",
"status": "rolled back"
},
{
"action": "delete",
"path": "/124",
"status": "failed",
"error": "resource not found"
},
..
]
Which HTTP status code is appropriate for responses to bulk requests?
With bulk requests we have the problem than some parts of the request might execute successfully while other fail. If everything worked it is easy, in this case we can simply return HTTP 200 OK.
Even if all requested changes fail it can be argued that HTTP 200 is still a valid response code as long as the bulk operation itself completed successfully.
In either way the client needs to process the response body to get detailed information about the processing status.
Another idea that might come in mind is HTTP 207 (Multi-status). HTTP 207 is part of RFC 4918 (HTTP extensions for WebDAV) and described like this:
A Multi-Status response conveys information about multiple resources in situations where multiple status codes might be appropriate. [..] Although '207' is used as the overall response status code, the recipient needs to consult the contents of the multistatus response body for further information about the success or failure of the method execution. The response MAY be used in success, partial success and also in failure situations.
So far this reads like a great fit.
Unfortunately HTTP 207 is part of the Webdav specification and requires a specific response body format that looks like this:
<?xml version="1.0" encoding="utf-8" ?>
<d:multistatus xmlns:d="DAV:">
<d:response>
<d:href>http://www.example.com/container/resource3</d:href>
<d:status>HTTP/1.1 423 Locked</d:status>
<d:error><d:lock-token-submitted/></d:error>
</d:response>
</d:multistatus>
This is likely not the response format you want. Some might argue that it is fine to reuse HTTP 207 with a custom response format. Personally I would not recommend doing this and instead use a simple HTTP 200 status code.
In case you the bulk request is processed asynchronously HTTP 202 (Accepted) is the status code to use.
Summary
We looked at different approaches of building bulk APIs. All approaches have different up- and downsides. There is no single correct way as it always depends on your requirements.
If you need a generic way to submit multiple actions in a single request you can use a custom JSON format. Alternatively you can use a multipart content-type to merge multiple requests into a single request.
You can also come up with separate resources that that express the desired operation. This is usually the simplest and most pragmatic way if you only have one or a few operations that need to support bulk operations.
In all scenarios you should evaluate if bulk operations really produce the desired performance gains. Otherwise, the additional complexity of bulk operations is usually not worth the effort.
Interested in more REST related articles? Have a look at my REST API design page.